

NVIDIAは、全く新しい4nmプロセスノードを採用した次世代データセンター用パワーハウス、Hopper GH100 GPUを正式に発表しました。このGPUは、800億個のトランジスタを持つ絶対的なモンスターであり、市場のあらゆるGPUの中で最速のAIおよびコンピュート馬力を提供します。
NVIDIA Hopper GH100 GPUの公式発表。初の4nm&HBM3搭載データセンターチップ、800億トランジスタ、最大4000TFLOPsの馬力を持つ地球上で最速のAI/Compute製品
HopperアーキテクチャをベースにしたHopperは、最先端のTSMC 4nmプロセスノードで生産される工学的な驚異のGPUです
GPUです。
Hopper GH100は、これまでのデータセンター向けGPUと同様に、人工知能(AI)、機械学習(ML)、深層ニューラルネットワーキング(DNN)、およびHPCに焦点を当てた様々なコンピューティングワークロードをターゲットにしています。




※ 画像をクリックすると、別Window・タブで拡大します。
GPUは、すべてのHPC要件に対するワンゴー・ソリューションであり、そのサイズと性能の数字を見れば、1つのモンスター・チップと言えます。

新しいストリーミング・マルチプロセッサ(SM)は、多くのパフォーマンスと効率性を改善しました。主な新機能は以下の通りです。
- 新しい第4世代のTensor Coreは、SM単位の高速化、SM数の追加、H100の高クロックを含め、A100と比較してチップ間が最大で6倍高速化されています。SM単位では、前世代の16ビット浮動小数点オプションと比較して、同等のデータ型でA100 SMの2倍のMMA(Matrix MultiplyAccumulate)演算レート、新しいFP8データ型を用いたA100の4倍のレートをTensor Coresは実現しています。Sparsity機能は、深層学習ネットワークにおけるきめ細かい構造化されたスパース性を利用し、標準的なTensor Core演算の性能を2倍に向上させることができます。
- 新しいDPX命令は、ダイナミックプログラミングアルゴリズムをA100 GPUに比べて最大7倍高速化します。その例として、ゲノム処理のためのSmith-Watermanアルゴリズムと、動的な倉庫環境におけるロボット群の最適経路を見つけるために使用されるFloyd-Warshallアルゴリズムが挙げられます。
IEEE FP64 および FP32 の処理速度が、A100 と比較してチップ間比で 3 倍高速化。 - 新機能スレッド・ブロック・クラスターにより、1つのSM上の1つのスレッド・ブロックよりも大きな粒度で局所性をプログラムにより制御することができます。これは、CUDA プログラミング モデルを拡張するもので、プログラミング階層にもう 1 つのレベルを追加し、スレッド、スレッド ブロック、スレッド ブロック クラスタ、およびグリッドを含むようにします。クラスターでは、複数の SM で同時に実行される複数のスレッドブロックを同期させ、共同でデータをフェッチおよび交換することができます。
- 新しい非同期実行機能として、グローバルメモリと共有メモリ間で大きなデータブロックを非常に効率的に転送できる新しい Tensor Memory Accelerator (TMA) ユニットが含まれています。TMA は、クラスタ内のスレッドブロック間の非同期コピーもサポートします。また、アトミックなデータ移動と同期を行うための新しい非同期トランザクションバリアも用意されています。
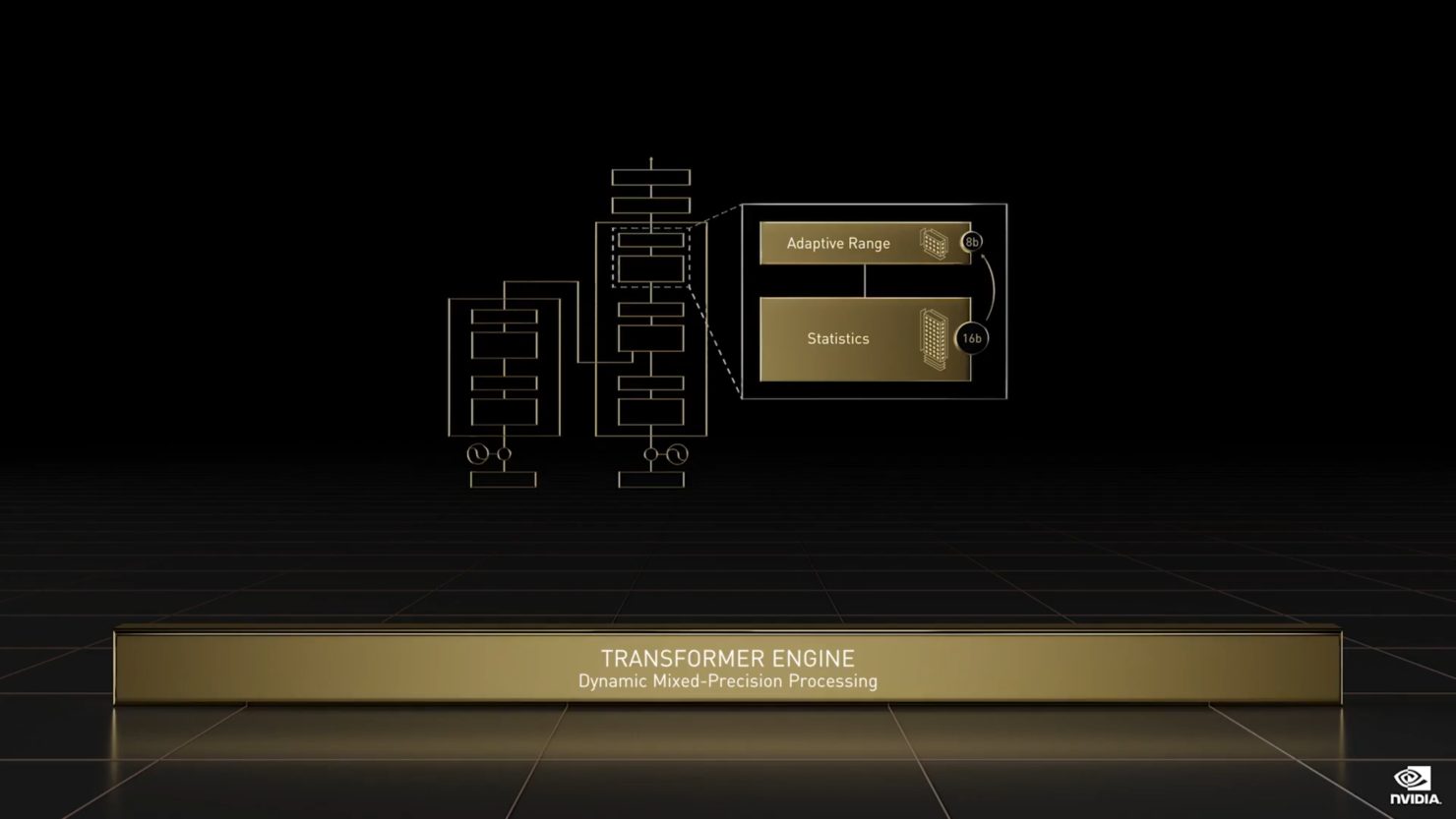
- 新しいTransformer Engineは、Transformerモデルの学習と推論を高速化するために特別に設計されたソフトウェアとカスタムHopper Tensor Coreテクノロジーの組み合わせを使用します。Transformer Engineは、FP8と16ビットの計算をインテリジェントに管理し、動的に選択することで、各レイヤーにおけるFP8と16ビット間のリキャストとスケーリングを自動的に行い、最大9倍のAIトレーニングと最大30倍の高速化を達成します。大規模言語モデルにおけるAI推論を前世代のA100と比較して高速化。
- HBM3メモリサブシステムにより、前世代と比較して約2倍の帯域幅を実現。H100 SXM5 GPUは、クラス最高レベルの3TB/秒のメモリ帯域幅を実現するHBM3メモリを搭載した世界初のGPUです。
- 50 MBのL2キャッシュ・アーキテクチャは、モデルやデータセットの大部分をキャッシュして繰り返しアクセスできるようにし、HBM3へのトリップを低減します。
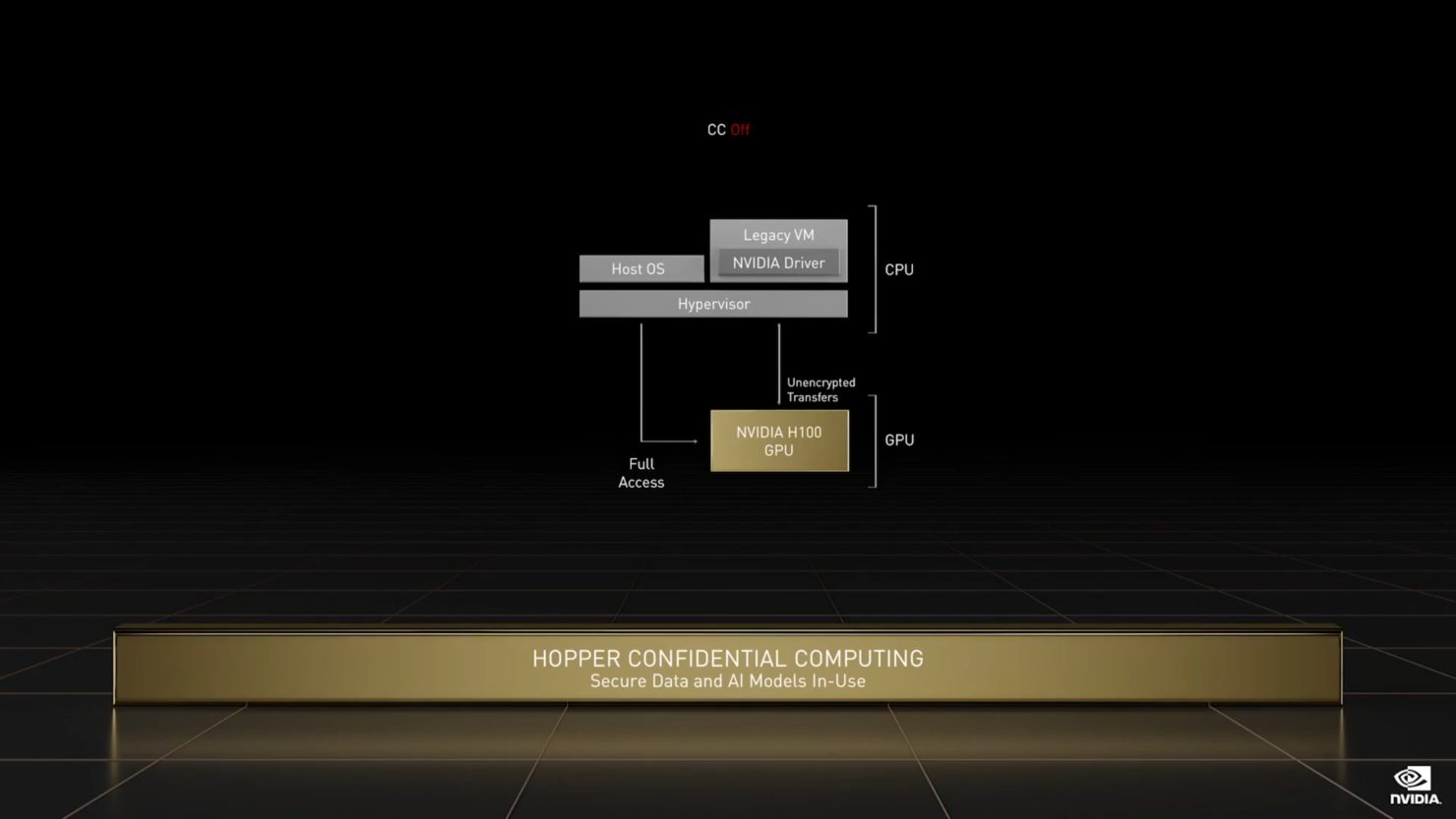
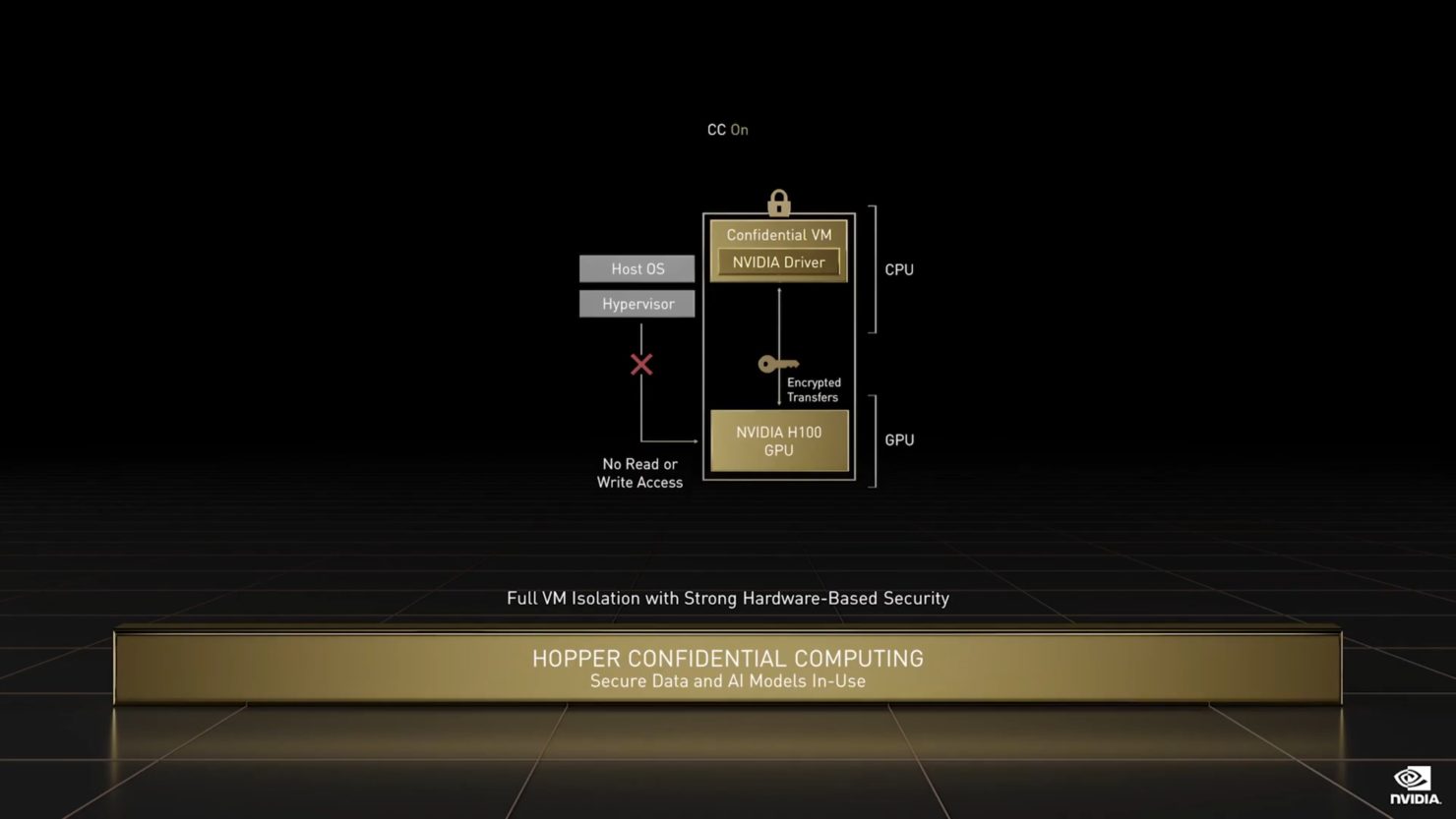
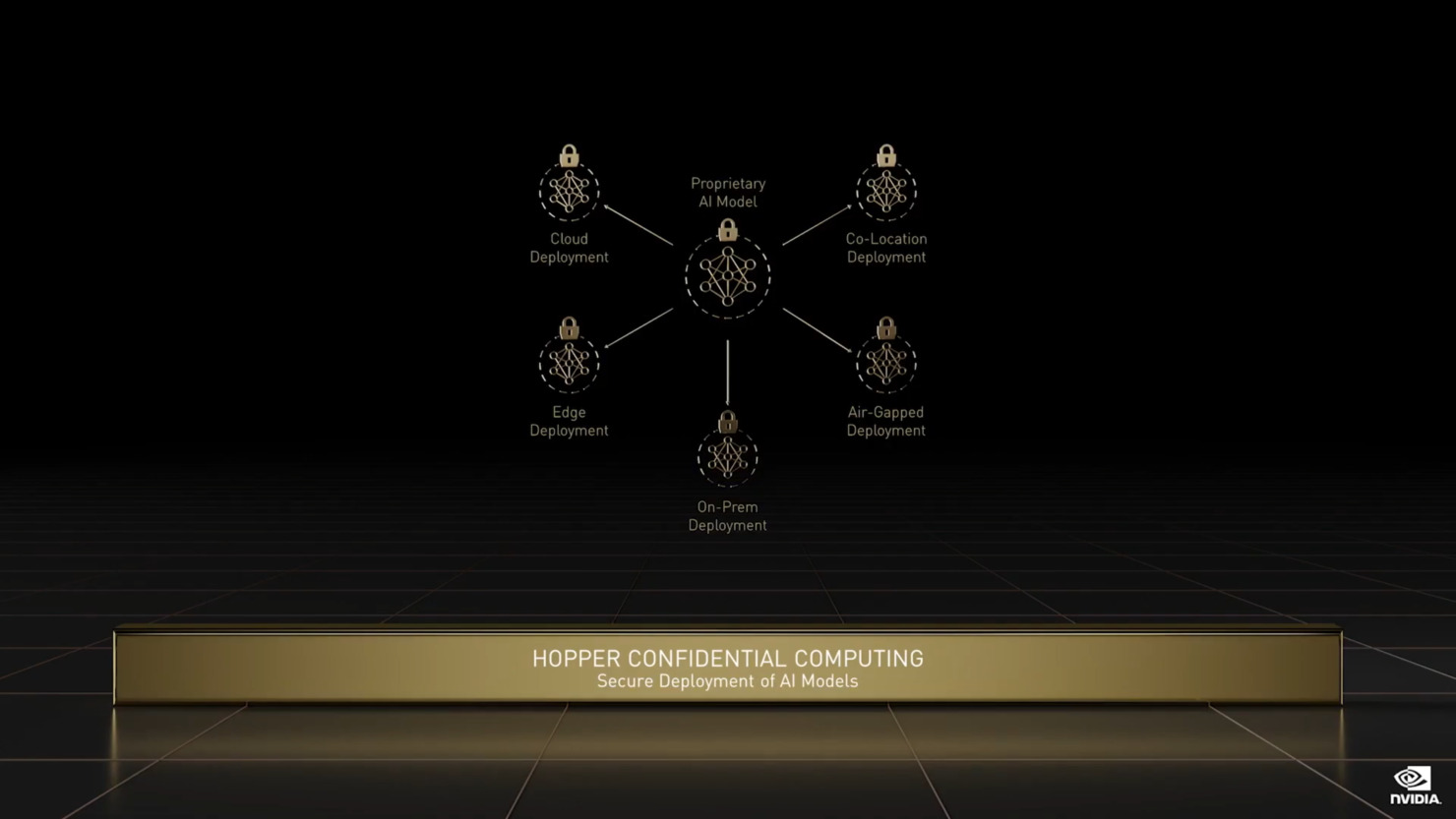
- NVIDIA H100 Tensor Core GPU アーキテクチャを A100 と比較。MIGレベルのTrusted Execution Environments (TEE)によるConfidential Computing機能が初めて提供されるようになった。最大7つのGPUインスタンスがサポートされ、それぞれが専用のNVDECとNVJPGユニットを備えています。各インスタンスには、NVIDIA開発者ツールで動作する独自のパフォーマンスモニタのセットが含まれるようになりました。
新しいコンフィデンシャル・コンピューティングのサポートは、ユーザデータの保護、ハードウェアおよびソフトウェア攻撃からの防御、仮想化およびMIG環境におけるVM同士の分離と保護を強化します。H100は、世界初のネイティブConfidential Computing GPUを実装し、Trusted Execution EnvironmentをPCIeフルラインレートのCPUで拡張します。 - 第4世代のNVIDIA NVLink®は、PCIe Gen 5の7倍の帯域幅で動作するマルチGPU IO用の900GB/秒の総帯域幅で、前世代のNVLinkに比べて、all-reduceオペレーションで3倍の帯域幅の増加、一般帯域幅で50%の増加を実現しています。
第3世代のNVSwitchテクノロジーには、サーバー、クラスタ、およびデータセンター環境において複数のGPUを接続するために、ノードの内側と外側の両方に存在するスイッチが含まれています。ノード内の各NVSwitchは、第4世代NVLinkリンクを64ポート提供し、マルチGPU接続を加速させます。スイッチの総スループットは、前世代の7.2 Tbits/secから13.6 Tbits/secに向上しています。新しい第3世代のNVSwitch技術は、マルチキャストとNVIDIA SHARPのインネットワーク削減による集団操作のためのハードウェアアクセラレーションも提供します。 - 新しいNVLinkスイッチシステムの相互接続技術と第3世代NVSwitch技術に基づく新しい第2レベルNVLinkスイッチは、アドレス空間の分離と保護を導入し、最大32ノードまたは256GPUを、2対1のテーパーファットツリートポロジーでNVLink上に接続できるようにします。これらの接続されたノードは、57.6TB/秒の全帯域幅を実現し、FP8スパースAIコンピュートで1エクサフロップという驚異的な処理能力を提供することができます。
- PCIe Gen5は、Gen4 PCIeの64GB/秒の総帯域幅(各方向32GB/秒)に対し、128GB/秒の総帯域幅(各方向64GB/秒)を提供します。PCIe Gen 5により、H100は最高性能のx86 CPUおよびSmartNIC/DPU(データ処理ユニット)とのインターフェイスが可能になります。
だから仕様に来る、NVIDIA Hopper GH100 GPU は、大規模な 144 SM (ストリーミング マルチプロセッサ) チップ レイアウトで構成されています、合計 8 GPC で紹介されていることです。これらの GPC は、さらに各 2 SM ユニットで構成されている 9 TPC の合計を揺する。
これにより、1GPCあたり18個のSMを搭載し、8GPC構成全体では144個となります。
各 SM は最大 128 個の FP32 ユニットで構成され、合計 18,432 個の CUDA コアを提供することになります。以下は、H100チップに期待される構成の一部です。
GH100 GPUのフル実装には、以下のユニットが含まれます:
- 8GPC、72TPC(9TPC/GPC)、2SMs/TPC、144SMs/フルGPU
- 128 FP32 CUDA コア/SM、18432 FP32 CUDA コア/フル GPU
- 第4世代Tensorコア(SMあたり4個、フルGPUあたり576個
- 6個のHBM3またはHBM2eスタック、12個の512ビットメモリコントローラ
- 60MB L2キャッシュ
- 第4世代のNVLinkとPCIe Gen 5
SXM5ボードフォームファクタのNVIDIA H100 GPUは、以下のユニットを搭載しています:
- 8 GPC、66 TPC、2 SMs/TPC、132 SMs/GPU。
- 128 FP32 CUDAコア/SM、16896 FP32 CUDAコア/GPU
- 第4世代Tensorコア 4個/SM、528個/GPU
- 80 GB HBM3、5 HBM3スタック、10 512ビットメモリコントローラ
- 50MB L2キャッシュ
- 第4世代のNVLinkとPCIe Gen 5
PCIe Gen 5ボードのフォームファクタを持つNVIDIA H100 GPUには、以下のユニットが含まれています:
- GPUあたり7または8のGPC、57のTPC、2 SMs/TPC、114 SMs
- 128 FP32 CUDA コア/SM, 14592 FP32 CUDA コア/GPU
- 第4世代Tensorコア(SMあたり4個)、GPUあたり456個
- 80 GB HBM2e、5 HBM2eスタック、10 512ビットメモリコントローラ
- 50MB L2キャッシュ
- 第4世代のNVLinkとPCIe Gen 5
これはGA100 GPUのフル構成と比較して2.25倍の増加です。NVIDIAは、Hopper GPUのFP64、FP16、Tensorコアの数を増やして、性能を大幅に向上させることも考えている。
また、IntelのPonte Vecchioも1:1のFP64を搭載すると見られており、これに対抗するためには必要不可欠なものとなっている。
※ 画像をクリックすると、別Window・タブで拡大します。
キャッシュもNVIDIAが力を入れている部分であり、Hopper GH100GPUでは48MBに増強されています。
これは、Ampere GA100 GPUに搭載された50MBキャッシュの20%増で、AMDのフラッグシップMCM GPUであるAldebaranのMI250Xの3倍のサイズとなる。
NVIDIA の GH100 Hopper GPU は、FP8 で 4000TFLOPs、FP16 で 2000TFLOPs、TF32 で 1000TFLOPs、FP64 で 60 TFLOPs の演算性能を提供する予定です。
この記録的な数値は、それ以前のすべてのHPCアクセラレータを凌駕するものです。
ちなみに、FP64演算では、NVIDIA社の自社製GPU「A100」の3.3倍、AMD社の「Instinct MI250X」の28%に相当する高速化を実現しています。
FP16では、A100の3倍、MI250Xの5.2倍と、文字通り桁違いの速さです。
NVIDIA GH100 GPUのブロック図:
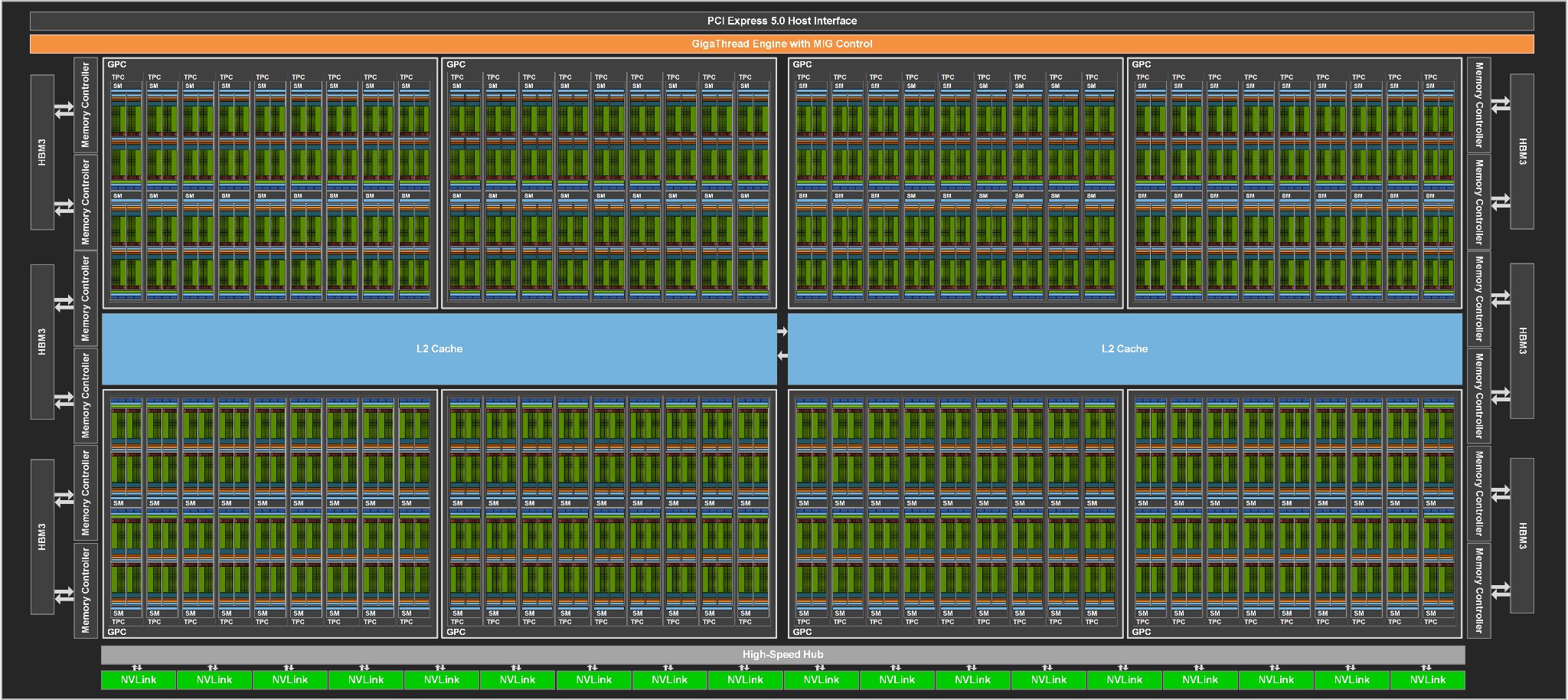
※ 画像をクリックすると、別Window・タブで拡大します。
第4世代NVIDIA Hopper GH100 GPU SM(Streaming Multiprocessor)の主な特徴は以下の通りです:
- SM単位の高速化、SM数の追加、H100の高クロックを含め、A100と比較してチップ間が最大6倍高速化されています。
- Tensor Cores は、SM 毎に、同等のデータ型において A100 SM の 2 倍の MMA (Matrix Multiply-Accumulate) 計算速度、新しい FP8 データ型を使用して、前世代の 16 ビット浮動小数点オプションと比較して、A100 の 4 倍の計算速度を実現しています。
- Sparsity機能は、深層学習ネットワークにおけるきめ細かい構造化されたスパース性を利用し、標準的なTensorコア演算の性能を2倍に向上させる。
- 新しいDPX命令は、ダイナミックプログラミングアルゴリズムをA100 GPUに比べて最大7倍高速化します。その例として、ゲノム処理のためのSmith-Watermanアルゴリズムと、動的な倉庫環境におけるロボット群の最適経路を見つけるために使用されるFloyd-Warshallアルゴリズムが挙げられます。
- IEEE FP64およびFP32の処理速度がA100比でチップ間3倍速い。これは、SMあたりのクロックが2倍速いことに加え、H100ではSM数が増え、クロックが高くなったためである。
- 共有メモリとL1データキャッシュを合わせて256KB、A100の1.33倍。
- 新しい非同期実行機能には、グローバルメモリと共有メモリ間で大きなデータブロックを効率的に転送できる新しいTensor Memory Accelerator(TMA)ユニットが含まれています。TMAは、クラスタ内のスレッドブロック間の非同期コピーもサポートしています。また、アトミックなデータ移動と同期を行うための新しい非同期トランザクションバリアも用意されています。
- 新しいスレッドブロッククラスター機能は、複数のSMにまたがるローカリティの制御を公開します。
- Distributed Shared Memoryは、複数のSMの共有メモリブロックにまたがるロード、ストア、アトミックについて、SM間の直接通信を可能にする。
NVIDIA GH100 SMブロック図:
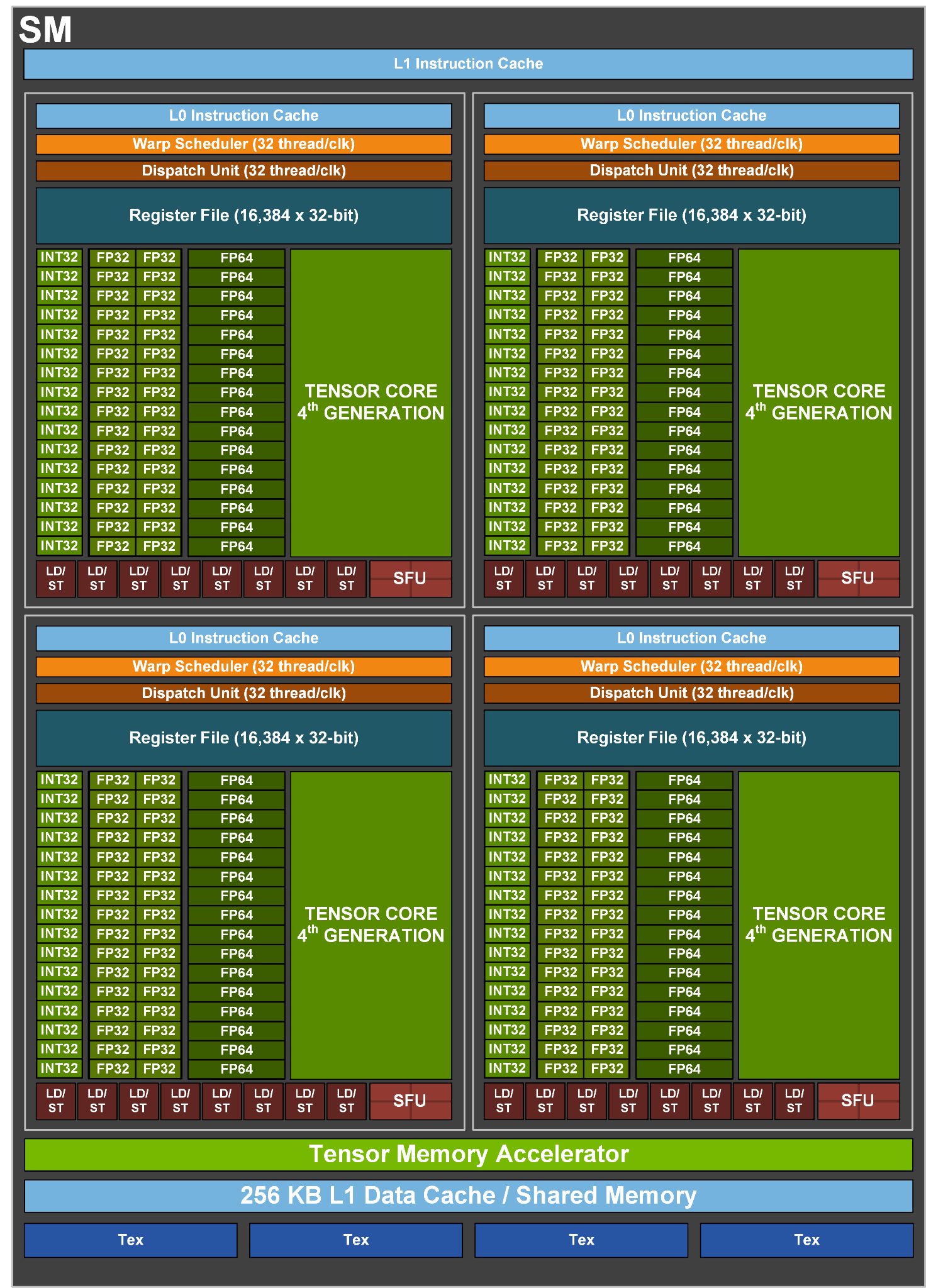
※ 画像をクリックすると、別Window・タブで拡大します。
メモリについては、NVIDIA Hopper GH100 GPUは、6144ビットのバスインターフェイスで動作し、A100のHBM2eメモリサブシステムに比べて50%増となる最大3TB/sの帯域幅を提供する全く新しいHBM3メモリを搭載しています。
各H100アクセラレータは80GBのメモリを搭載しますが、将来的にはA100 80GBのように2倍のメモリ容量構成になることが予想されます。
※ 画像をクリックすると、別Window・タブで拡大します。
このGPUは、最大128GB/秒の転送速度を持つPCIe Gen 5準拠と、900GB/秒のGPU間相互接続帯域幅を提供するNVLINKインターフェイスも備えています。
Hopper H100チップ全体では、4.9 TB/秒という驚異的な外部帯域幅を実現しています。
このモンスター性能のすべてが、700W(SXM)パッケージで提供されています。
PCIeバージョンは、最新のPCIe Gen 5コネクタを装備し、最大600Wの電力を可能にしますが、実際のPCIeバージョンは、TDP 350Wで動作します。
NVIDIA Hopper GH100コンピュート
| GPU | Kepler GK110 |
Maxwell GM200 |
Pascal GP100 |
Volta GV100 |
Ampere GA100 |
Hopper GH100 |
| 実行環境 デバイス世代 |
4 | 5 | 6 | 7 | 8 | 9/0 |
| ワープ辺りの スレッド数 |
32 | 32 | 32 | 32 | 32 | 32 |
| 最大ワープ数 / マルチプロセッサー | 64 | 64 | 64 | 64 | 64 | 64 |
| 最大スレッド数 / マルチプロセッサー | 2,048 | 2,048 | 2,048 | 2,048 | 2,048 | 2,048 |
| 最大スレッド ブロック数 / マルチプロセッサー |
16 | 32 | 32 | 32 | 32 | 32 |
| 大罪32bit レジスタ数 / SM |
65,536 | 65,536 | 65,536 | 65,536 | 65,536 | 65,536 |
| 最大レジスタ数 / ブロック |
65,536 | 32,768 | 65,536 | 65,536 | 65,536 | 65,536 |
| 最大レジスタ数 / スレッド |
255 | 255 | 255 | 255 | 255 | 255 |
| 最大スレッド ブックサイズ |
1,024 | 1,024 | 1,024 | 1,024 | 1,024 | 1,024 |
| CUDAコア数 / SM |
192 | 128 | 64 | 64 | 64 | 128 |
| 共有メモリサイズ / SM 構成 (bytes) |
16K/32K/48K | 96K | 64K | 96K | 164K | 228K |
NVIDIA Ampere GA100 GPUベースのA100のスペック:
| NVIDIA Tesla グラフィック カード |
NVIDIA H100 (SMX5) |
NVIDIA H100 (PCIe) |
NVIDIA A100 (SXM4) |
NVIDIA A100 (PCIe4) |
Tesla V100S (PCIe) |
Tesla V100 (SXM2) |
Tesla P100 (SXM2) |
Tesla P100 (PCI-Express) |
Tesla M40 (PCI-Express) |
Tesla K40 (PCI-Express) |
| GPU | GH100 (Hopper) |
GH100 (Hopper) |
GA100 (Ampere) |
GA100 (Ampere) |
GV100 (Volta) | GV100 (Volta) | GP100 (Pascal) |
GP100 (Pascal) |
GM200 (Maxwell) | GK110 (Kepler) |
| 製造プロセス | 4nm | 4nm | 7nm | 7nm | 12nm | 12nm | 16nm | 16nm | 28nm | 28nm |
| トランジスタ数 | 800億 | 800億 | 542億 | 542億 | 211億 | 211億 | 153億 | 153億 | 80億 | 71億 |
| GPUダイサイズ | 814mm2 | 814mm2 | 826mm2 | 826mm2 | 815mm2 | 815mm2 | 610 mm2 | 610 mm2 | 601 mm2 | 551 mm2 |
| SM数 | 132 | 114 | 108 | 108 | 80 | 80 | 56 | 56 | 24 | 15 |
| TPC数 | 66 | 57 | 54 | 54 | 40 | 40 | 28 | 28 | 24 | 15 |
| SM当りのFP32 CUDA コア数 |
128 | 128 | 64 | 64 | 64 | 64 | 64 | 64 | 128 | 192 |
| FP64 CUDA コア数 / SM |
128 | 128 | 32 | 32 | 32 | 32 | 32 | 32 | 4 | 64 |
| FP32 CUDA コア数 |
16,896 | 14,592 | 6,912 | 6,912 | 5,120 | 5,120 | 3,584 | 3,584 | 3,072 | 2,880 |
| FP64 CUDA コア数 |
16,896 | 14,592 | 3,456 | 3,456 | 2,560 | 2,560 | 1,792 | 1,792 | 96 | 960 |
| Tensorコア数 | 528 | 456 | 432 | 432 | 640 | 640 | N/A | N/A | N/A | N/A |
| テクスチャ ユニット数 |
528 | 456 | 432 | 432 | 320 | 320 | 224 | 224 | 192 | 240 |
| ブースト クロック |
不明 | 不明 | 1410 MHz | 1410 MHz | 1601 MHz | 1530 MHz | 1480 MHz | 1329MHz | 1114 MHz | 875 MHz |
| TOP数 (DNN/AI) |
2000 TOPs 4000 TOPs |
1600 TOPs 3200 TOPs |
1248 TOPs 2496 TOPs with Sparsity |
1248 TOPs 2496 TOPs with Sparsity |
130 TOPs | 125 TOPs | N/A | N/A | N/A | N/A |
| FP16演算性能 | 2000 TFLOPs | 1600 TFLOPs | 312 TFLOPs 624 TFLOPs with Sparsity |
312 TFLOPs 624 TFLOPs with Sparsity |
32.8 TFLOPs | 30.4 TFLOPs | 21.2 TFLOPs | 18.7 TFLOPs | N/A | N/A |
| FP32演算性能 | 1000 TFLOPs | 800 TFLOPs | 156 TFLOPs (19.5 TFLOPs standard) |
156 TFLOPs (19.5 TFLOPs standard) |
16.4 TFLOPs | 15.7 TFLOPs | 10.6 TFLOPs | 10.0 TFLOPs | 6.8 TFLOPs | 5.04 TFLOPs |
| FP64演算性能 | 60 TFLOPs | 48 TFLOPs | 19.5 TFLOPs (9.7 TFLOPs standard) |
19.5 TFLOPs (9.7 TFLOPs standard) |
8.2 TFLOPs | 7.80 TFLOPs | 5.30 TFLOPs | 4.7 TFLOPs | 0.2 TFLOPs | 1.68 TFLOPs |
| メモリインター フェイス |
5120-bit HBM2e | 5120-bit HBM3 | 6144-bit HBM2e | 6144-bit HBM2e | 4096-bit HBM2 | 4096-bit HBM2 | 4096-bit HBM2 | 4096-bit HBM2 | 384-bit GDDR5 | 384-bit GDDR5 |
| メモリ容量 | 最大80 GB HBM3 @ 3.0 Gbps | 最大80 GB HBM2e @ 2.0 Gbps | 最大 40 GB HBM2 @ 1.6 TB/s 最大80 GB HBM2 @ 1.6 TB/s |
最大 40 GB HBM2 @ 1.6 TB/s 最大 80 GB HBM2 @ 2.0 TB/s |
16 GB HBM2 @ 1134 GB/s | 16 GB HBM2 @ 900 GB/s | 16 GB HBM2 @ 732 GB/s | 16 GB HBM2 @ 732 GB/s 12 GB HBM2 @ 549 GB/s |
24 GB GDDR5 @ 288 GB/s | 12 GB GDDR5 @ 288 GB/s |
| L2 キャッシュ | 51200 KB | 51200 KB | 40960 KB | 40960 KB | 6144 KB | 6144 KB | 4096 KB | 4096 KB | 3072 KB | 1536 KB |
| TDP | 700W | 350W | 400W | 250W | 250W | 300W | 300W | 250W | 250W | 235W |
解説:
Hopperは5nmではなく、4nmだそうです。
GTC2022が開催され、どこもこの話題で持ち切りですので、サーバー向けのGPUは興味がないのですが、一応nVidiaの次世代だし、取り上げてみます。
ただし、あまりやる気はないです。
HopperはLovelaceがRDNA3にどうしても勝てなかった場合、MCMを採用するチップ(GH102?)をGeforceとして出すというような話が出ています。
しかし、今回の仕様を見るとゲーム向けとしては無駄が多く、恐らく、AD102を徹底的にOCして何とかするのではないかと思います。
RTX4090Ti(?)は800W以上とも言われていますし、そこまでやるからにはHopperの出番はないのかなと思います。
IntelのGaudi 2 HL 2080はHopperと互角と言われていますが、今回TSMCの4nmを採用すると聞いてホントかな?と思いました。
GH100にはMCMを採用せず、巨大なモノリシックで行くのはnVidiaはMCMにあまり肯定的ではないのかなと感じました。
AppleのM1 UltraもM1を2つくっつけて単純に2倍の性能になっているわけではありませんし、やはり、チップ間の通信がボトルネックになる可能性を考えると、サーバー向けのフラッグシップは巨大なモノリシックにした方が良いと思ったのかもしれませんね。
早々にMCMを採用するAMDと様子見しながらと言うnVidia、両社のスタンスがはっきりしているところですね。
Voltaはゲーム向けとして出ましたが、性能は今一つでPascalのTITANと同程度の性能でした。
Hopperもゲーマーには関係のない製品になるのかなと思います。
Copyright © 2022 自作ユーザーが解説するゲーミングPCガイド All Rights Reserved.